Introduction: Memory That Learns to Remember
Imagine a diligent archivist who keeps the records of every event, conversation, and emotion that defines a company’s history. Yet, this archivist also has a unique talent — they can decide which memories to preserve, which to discard, and which to use for current decision-making. This archivist is a fitting metaphor for an LSTM (Long Short-Term Memory) network. This structure gives machines the ability to “remember” patterns over time, much like how we connect present actions with distant past experiences.
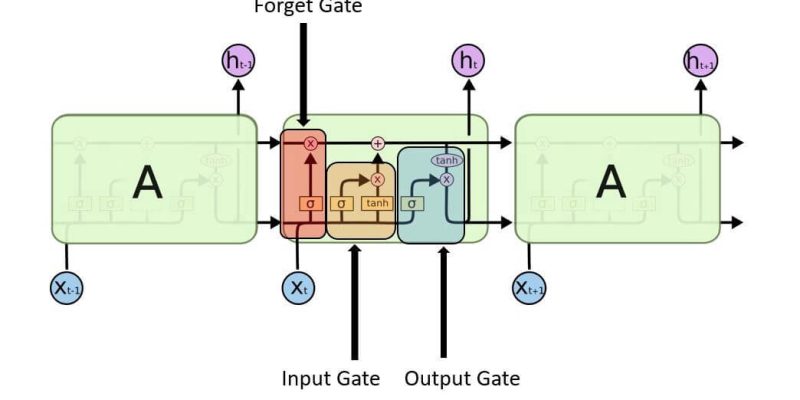
In the realm of sequence data — such as speech, time-series analytics, or natural language processing — traditional neural networks struggled to recall context beyond a few steps. LSTM emerged as a solution, introducing a controlled memory mechanism that mimics human-like selective recall. To grasp how this happens, we need to open the vault of the LSTM’s memory cell and look at its three gatekeepers — the input, forget, and output gates.
The Symphony of Controlled Memory
The beauty of an LSTM lies in how it balances remembering and forgetting. It doesn’t store every bit of information flowing through it, as that would lead to confusion and inefficiency. Instead, it orchestrates memory with discipline — akin to a symphony where each instrument knows when to play and when to stay silent. This orchestration allows LSTM networks to process information across long intervals without losing relevance.
When applied in real-world scenarios like predicting stock movements or understanding the sentiment behind a tweet, the LSTM’s gates operate with precision. They filter noise, retain value, and discard irrelevance — enabling machines to form meaningful temporal connections. This delicate control mechanism is explored by students in a Data Science course in Nashik, where understanding LSTM architectures becomes vital for mastering predictive modelling and deep learning.
The Input Gate: The Selective Gatekeeper
The input gate is like an editor who decides which parts of a manuscript are worth publishing. It determines how much of the new information entering the network should influence the cell’s current state. Technically, it takes the current input and previous hidden state, applies a sigmoid activation to produce a range between 0 and 1, and multiplies it by a candidate memory vector.
This process ensures that only valuable insights — not random fluctuations — get encoded into the network’s long-term memory. In practice, it means that an LSTM processing financial data can differentiate between a temporary market dip and a meaningful long-term trend. Such an understanding reflects the analytical foundation taught in a Data Scientist course, where learners go beyond theoretical formulas to interpret how these gates underpin reliable forecasting systems.
The Forget Gate: The Art of Letting Go
If the input gate is about inclusion, the forget gate is about wisdom — knowing what to leave behind. It decides which information should fade from memory, ensuring that the network doesn’t get bogged down by obsolete patterns. The forget gate applies a sigmoid activation that scales old cell states between 0 (forget completely) and 1 (retain fully).
Imagine a seasoned chess player who doesn’t dwell on every past move but remembers the key strategies that shaped the game. Similarly, the forget gate helps the LSTM stay focused on what matters for the current context. This selective amnesia is crucial when analysing sequences where older data may no longer influence the outcome, like recent consumer behaviour trends overtaking last year’s data. Such insights are critical for those engaged in a Data Science course in Nashik, where learning to interpret long-term dependencies can transform raw data into actionable intelligence.
The Output Gate: The Voice of the Present
Once the network has updated and refined its internal state, it needs to decide what to communicate externally — and that’s where the output gate steps in. It acts like a spokesperson who synthesises the most relevant details from an entire meeting before making a public statement. The output gate uses a sigmoid activation to determine what portion of the memory cell should influence the current output.
This mechanism ensures that the LSTM’s predictions or representations are contextually rich yet concise. In language models, the network can generate the next word based on both immediate input and distant context — producing text that feels coherent and meaningful. In industrial applications, it means that machines can forecast future demand or anomalies by weighing the right signals at the right time, a skill that practitioners refine during a Data Scientist course focused on deep learning frameworks.
The Hidden State: Where Time Meets Memory
Beneath the visible interactions of gates lies the hidden state — a continuous thread connecting one moment to the next. It carries forward both short-term and long-term information, refined by the gates’ selective processes. Think of it as a river that adapts its flow depending on the terrain, ensuring continuity without stagnation.
This hidden state allows LSTMs to model complex temporal dynamics, such as speech intonation or sensor readings, that depend on both current and past contexts. It’s not just memory — it’s intelligent continuity. This subtle mastery of time-series behaviour is what makes LSTMs indispensable in today’s predictive analytics landscape.
Conclusion: Machines That Remember What Matters
In the grand narrative of artificial intelligence, LSTM stands out as a bridge between memory and foresight. By mastering the balance between remembering and forgetting through its trio of gates, the system empowers itself to capture meaning across time. The input gate welcomes valuable insights, the forget gate clears away clutter, and the output gate articulates what’s worth expressing — together forming a memory system that’s both disciplined and dynamic.
For data-driven professionals, understanding this architecture isn’t just about mathematical curiosity. It’s about learning how machines perceive continuity — how they turn scattered data points into evolving stories. And for those pursuing advanced learning through a Data Science course in Nashik, exploring LSTMs marks a pivotal step in becoming the kind of professional who doesn’t just analyse data but interprets the rhythm of change itself.
For more details visit us:
Name: ExcelR – Data Science, Data Analyst Course in Nashik
Address: Impact Spaces, Office no 1, 1st Floor, Shree Sai Siddhi Plaza,Next to Indian Oil Petrol Pump, Near ITI Signal,Trambakeshwar Road, Mahatma Nagar,Nashik,Maharastra 422005
Phone: 072040 43317
Email: enquiry@excelr.com





Comments